如何定義 Clustering 的數目與類別(二):用數據方法找出合理分群數目
2026-05-22

方法一:Elbow Method
Elbow Method(手肘法) 是用來幫助我們決定 K-means 應該分成幾多群,即 K 值 的判斷方法。
因為 K-means 要先指定 K,但K-means 的缺點之一是 不容易識別正確的 K 值;所以 Elbow Method 就是一個常用的輔助方法。Elbow Method 主要用來觀察不同 K 值下的 群內誤差 是否明顯下降。當 K 增加時,cluster 內的資料會變得更集中,誤差通常會下降。但當下降幅度開始變慢時,那個轉折點就像手肘一樣,稱為 elbow point。
例如:剛才我了解業務後得出4–5 個候選群組測試 ,所以可以是K = 2 至 K = 6:
Elbow Method 看什麼?
| K 值 | 分群解讀 |
|---|---|
| K = 2 | 分得太粗,只能看出高活躍與低活躍 |
| K = 3 | 開始看出主要行為差異 |
| K = 4 | 分群變得較清晰 |
| K = 5 | 可對應到較完整的業務類型 |
| K = 6 | 可能開始過度細分,業務解釋成本增加 |
如果 K=5 之後誤差下降幅度不大,就可以把 K=5 視為候選分群數目。
Elbow Method的分數怎樣解讀?
Elbow Method 的想法是:
當 K 增加時,分群誤差會下降;但下降到某一點後,再增加 K,改善幅度會變得很小。這個轉折點就像手肘,所以叫 Elbow。
簡單講:
找出「再增加 cluster 也沒有太大幫助」的位置。
例如:
| K | Inertia / Error |
|---|---|
| 1 | 1000 |
| 2 | 650 |
| 3 | 420 |
| 4 | 280 |
| 5 | 250 |
| 6 | 240 |
你會發現由 K=1 到 K=4,error 下降很多;但 K=5、K=6 之後改善很少。
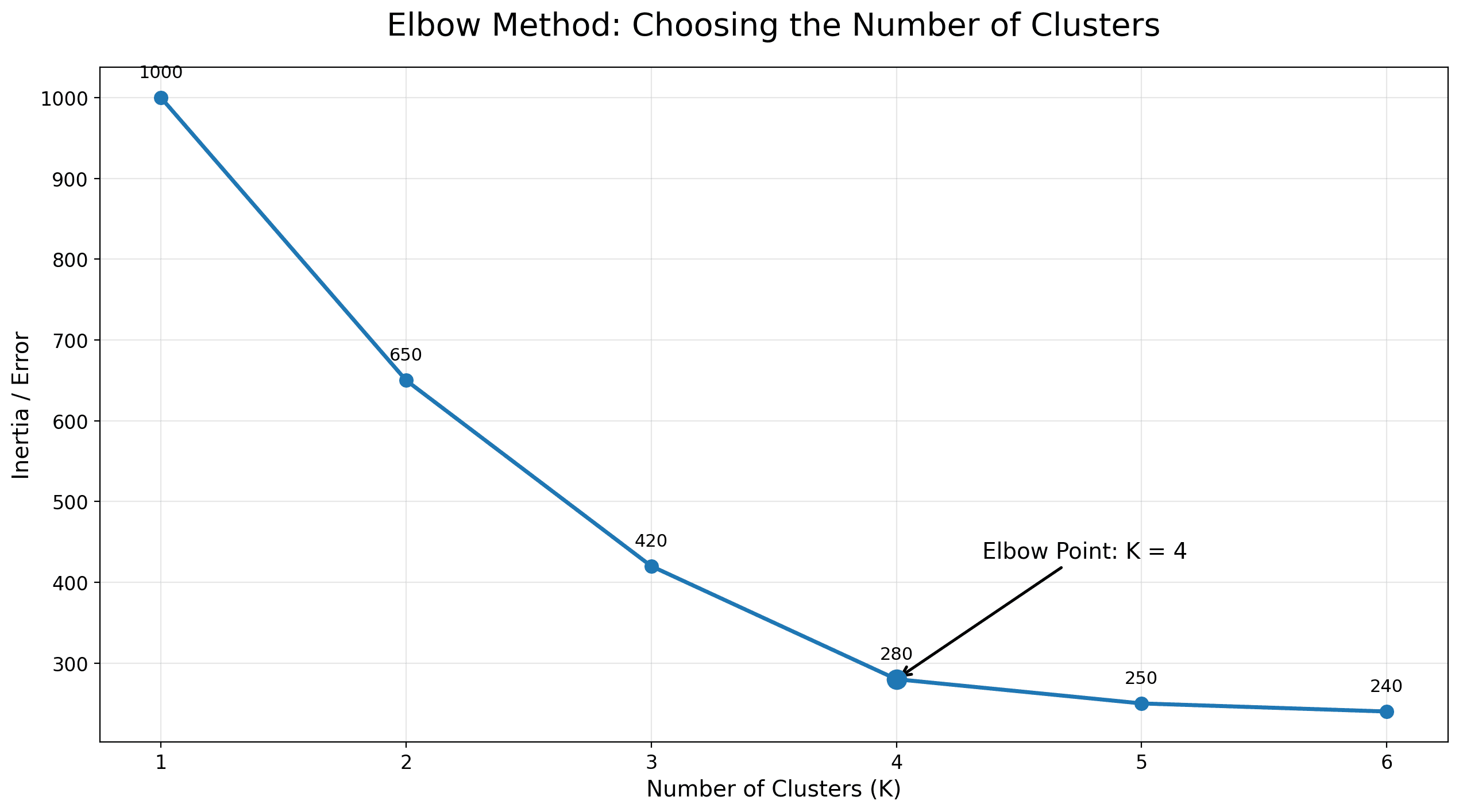
這代表:
K=4 可能是合理候選,因為再增加 cluster,幫助不大。
方法二:Silhouette Score
Silhouette Score 是另一個用來判斷 K-means 應該選幾多個 clusters 的方法。
如果說 Elbow Method 是看「再增加 K,error 是否仍然明顯下降」,
那麼 Silhouette Score 就是看:
分出來的群組是否夠清楚、夠分開。
Silhouette Score 會檢查:
- 同一 cluster 內的用戶是否相似
- 不同 cluster 之間是否分得夠開
Silhouette Score 看什麼?
它主要看兩件事:
| 檢查項目 | 意思 |
|---|---|
| 同一群內是否相似 | Cluster 內的用戶是否行為接近 |
| 不同群之間是否分開 | 不同 cluster 是否有明顯差異 |
簡單講:
好的 clustering 應該是:同一群內很相似,不同群之間很不同。
Silhouette Score 的分數怎樣解讀?
Silhouette Score 通常介乎 -1 到 1。
| Score | 解讀 |
|---|---|
| 接近 1 | 分群很好,群內相似、群與群分得開 |
| 接近 0 | 群組邊界模糊,有些用戶不知應屬哪一群 |
| 小於 0 | 可能分錯群,用戶可能更接近另一個 cluster |
例如:
| K | Silhouette Score |
|---|---|
| 2 | 0.42 |
| 3 | 0.51 |
| 4 | 0.58 |
| 5 | 0.55 |
| 6 | 0.48 |
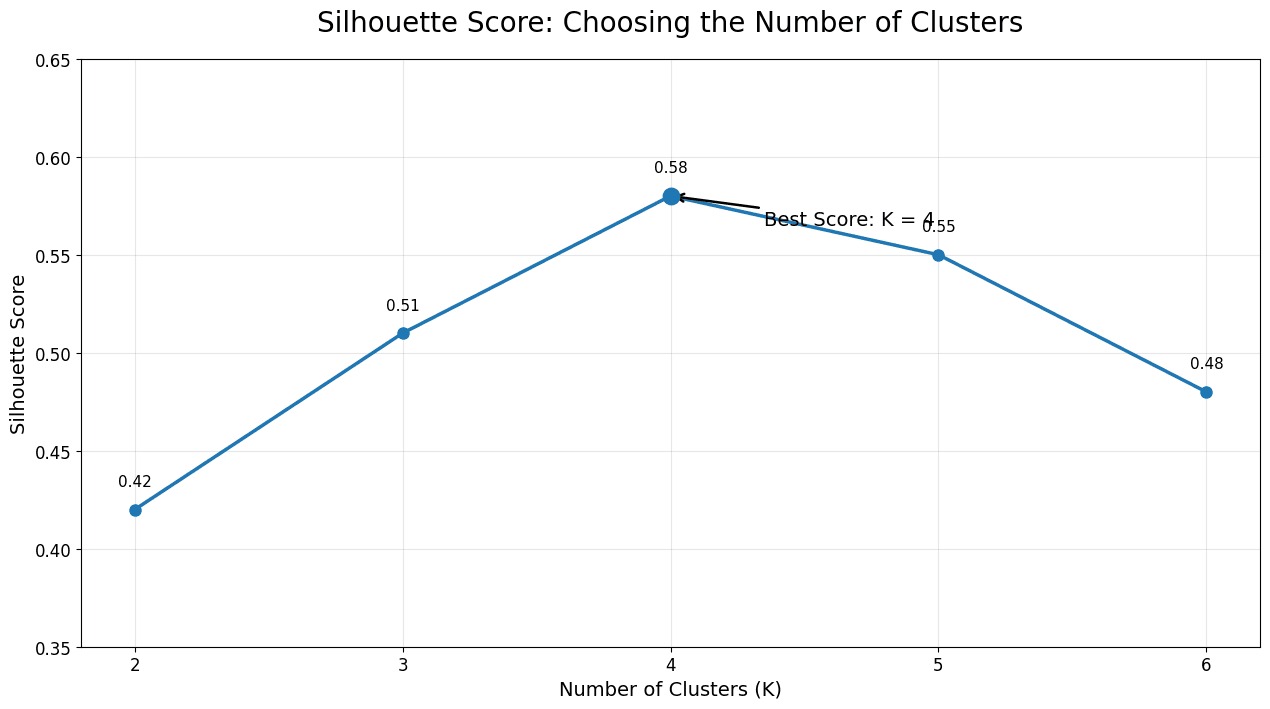
這個例子中,K = 4 的分數最高,所以 K=4 是一個合理候選。
在實務上,K 值不應只靠單一方法決定。Elbow Method 可以先用來收窄合理的 K 值範圍,找出增加 cluster 後改善幅度開始變小的位置;然後再透過 Silhouette Score 比較不同 K 值的分群清晰度,確認哪一個 clustering result 最能做到「群內相似、群間分明」。
合理數與業務群的最後考慮
最後,配合 UX / Business 判斷,確保每一個 cluster 都能被命名、理解,並轉化成具體產品策略。
如果數據方法顯示 K=4 較合理,但 business logic 初步分出 5 類,代表原本 5 個業務假設中,可能有兩類在真實數據上行為太相似,需要合併;或者 K=5 雖然數學分數稍低,但仍然有業務價值,可以保留作策略分群。
情況一:K=4 是數據上最合理
假設 Elbow Method 在 K=4 出現明顯轉折,而 Silhouette Score 也是 K=4 最高,代表資料自然分成 4 群比較清晰。
原本 business logic 分出 5 類:
| Business Logic 5 類 | 可能的數據結果 |
|---|---|
| 高活躍忠實用戶 | 獨立成一群 |
| 中活躍潛力用戶 | 可能與內容瀏覽用戶重疊 |
| 優惠導向用戶 | 獨立成一群 |
| 內容瀏覽用戶 | 可能與中活躍潛力用戶重疊 |
| 低活躍 / 流失風險用戶 | 獨立成一群 |
這時可合併成 4 類:
| 最終 K=4 類別 | 解釋 |
|---|---|
| 高活躍忠實用戶 | 高 session、高 PV、高互動 |
| 中活躍內容潛力用戶 | 有定期使用,主要看內容,但互動仍可提升 |
| 優惠導向用戶 | Jetso / Reward click 明顯較高 |
| 低活躍 / 流失風險用戶 | session 低、last visit days 高 |
即是把原本的:
中活躍潛力用戶 + 內容瀏覽用戶
合併成:
中活躍內容潛力用戶
因為在數據上,他們可能同樣都是「有使用,但未形成深度互動」的群組。
情況二:Business 仍想保留 5 類
如果 K=5 的 Silhouette Score 只比 K=4 稍低,例如:
| K | Silhouette Score | Business 解釋 |
|---|---|---|
| 4 | 0.56 | 數據最清晰 |
| 5 | 0.53 | 分群仍可接受,而且更能對應營運策略 |
| 6 | 0.45 | 開始過度細分 |
這時可以選擇 K=5,但要有理由:
雖然 K=4 在數學指標上略佳,但 K=5 能更清楚區分「中活躍潛力用戶」與「內容瀏覽用戶」,而這兩類用戶對應的產品策略不同,因此 K=5 在業務行動上更有價值。
例如:
| K=5 類別 | 策略差異 |
|---|---|
| 中活躍潛力用戶 | 用任務、簽到、個人化推薦提升使用頻率 |
| 內容瀏覽用戶 | 用 related content、AI Search、收藏、topic follow 提升內容探索 |
如果兩類對應的 action 不同,保留 K=5 是合理的。
決定原則
可以用三個問題決定:
| 判斷問題 | 如果答案是 Yes |
|---|---|
| K=5 的分群清晰度是否仍可接受? | 可以考慮 K=5 |
| 第 5 類是否有足夠用戶量? | 可以保留 |
| 第 5 類是否有不同產品 / marketing 策略? | 可以保留 |
如果第 5 類只是數據上很細、用戶量很少、策略又和其他群相似,就應該回到 K=4。
結論
如果 Elbow Method 和 Silhouette Score 顯示 K=4 是較合理的分群數目,但 business logic 初步定義了 5 類用戶,這代表原本的業務分類需要再被數據驗證。實際做法不是強行保留 5 類,而是比較 K=4 和 K=5 的分群結果。如果 K=4 的分群更清晰,且其中兩類用戶在行為上高度相似,便應將它們合併;例如將「中活躍潛力用戶」與「內容瀏覽用戶」合併為「中活躍內容潛力用戶」。相反,如果 K=5 雖然數學分數略低,但每一群都有足夠用戶量、能被清楚命名,並能對應不同產品或營運策略,則 K=5 仍然可以被視為合理選擇。最終的 K 值應在數據清晰度與業務可行動性之間取得平衡。